
hic数据分析

hic数据分析
kuteliyafukaHic上游分析
hic-pro整理
前言:
总体hic-pro是不如nfcore/hic的,无论是使用的简便性/报错的可读性/步骤的深度,都是。因为nfcore/hic本身便是hic-pro同一作者的改进。
但是我暂时依旧使用hic-pro,因为有苏卓杰写的整理qc的脚本。
下载数据
首先,登陆hpc的登陆节点,打开tmux,进入ob的文件夹。
1 | ./obsutil share-cp https://e-share.obs-website.cn-north-1.myhuaweicloud.com?token=cQTPwPGN6seCWf5euiwv4KFDcsSeV65pxwBPH1Iy+B9XF8goRmU+LNNz+aBcggMiS0dZceY8ha8w4FVoI+XxURfrARiZXt66ieqyQTtpVpsQNt3NbnjLDi2L2Yd7nYZTu9QkuZtrXkSBVIdjkXsWBCN5Ijcp4ANtdIqXRyV8yq8u3iu2V2nlw427/JNEn89GFMhN20pkFZfLz+l/W/hVJy7iewjF6TJTWZXfDXRV3VcQbrjiGXl4ccuRrEx+t1GMsXlFRdnyXFv0+So+rPhfthzPLJFjkuPUmx0250rVhfjo3cTQg7VxemdM1GPNuKL7Te4MzLBqpELJQoee9+rHJj3LS/nlk98HhNT21+ZomLX3+tLcwpZAH3WBEAzVBHbi1y1dLQ0wLjy0iNp9WI6923Stjs74lnigqRWTU2IG521cK4M3PdKdlPGopHkcLfq+0NPQJDISCsnIL+nVFzdhzF7WonO3rbNlkTfOXE8nGzP4u6wQPH6mrfuK3UNIcv3Ykn0dk1+eplbpio4eUsjgcu3Hb6jjFxE16OSULBG4hH/lVv+0saTcImssaGp9f0d1bPLmBnKzLbq13Jvqc5krg7zng/iwhDft+6PZdypDksYE8fZH5boPKcE4lBdOyLbVL8AdxQxk+oMn6sqXg+/R3TADvHzaCmAmUJ4KVFy2EZUU10IhCr0h7SXkd2CtMWu2 /storage/zhangkaiLab/shared/data/collaborators/Hanjie_Li/data/new_data -ac=176130 -f -r -vmd5 |
更改路径/网址/密码即可。
之后通过scp命令将文件传至实验室服务器
1 | scp -r /storage/zhangkaiLab/shared/data/collaborators/Hanjie_Li/HiC kunpeng@172.16.75.119:/data2/kunpeng/HiC/data/ |
同样修改路径
运行hic-pro
步骤1:
整理fastq数据,要求每个样本一个文件夹,注意文件命名_R?.fastq.gz
步骤2:
配置config文件,同样修改路径即可。(可能不需要配置了,用之前的就好)
步骤3:
进入hic的conda环境
1 | /data2/kunpeng/HiC/env/HiC-Pro_3.1.0/bin/HiC-Pro -i /data2/kunpeng/HiC/data/HiC/hic1/data -o /data2/kunpeng/HiC/data/HiC/hic1/run/result3 -c /data2/kunpeng/HiC/env/restriction_files/config/config-hicpro.txt |
修改input和output路径,运行hic-pro
运行summary.qc脚本
位于/data2/kunpeng/HiC/env/SZJ_example中,运行之后可以得到qc表格
下游分析需要nfcore/hic
生成.cool文件,之后对.cool文件进行可视化,看到contact map。
剩余关于找compartment/TAD/loops的下游分析还没仔细看,不过nfcore的pipeline里面都有
Hic质控标准
质控过程简略版: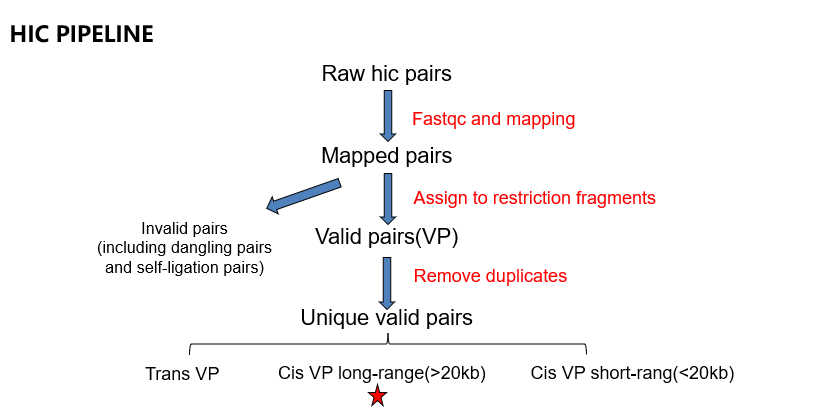
质控标准: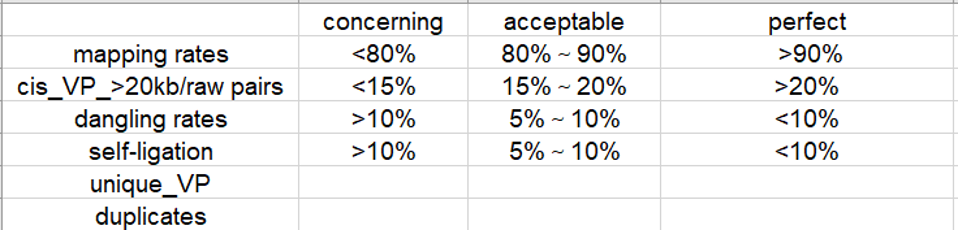
这里写错了,dangling%和religation%的perfect应该在5%以内。
note: dangling pairs指配对的两个reads均来自同一restriction fragment,反映该DNA片段酶切后未成功连接,通常由于连接(ligation)步骤效率不佳所致
另外,询问zj得知,测序仪的选择对文库复杂度的计算影响重大,T7非常容易得到低dup%。同一文库,变化可以达到10M 20% dup%,1000M 5% dup%。
200G是最低标准,如果不确定文库复杂度,那么可以梯度测2G,50G,500G。



